Advanced JABS usage
Active Learning Strategy in JABS
Active Learning is a semi-supervised Machine Learning (ML) strategy. The basic principle is that the data set and the model are built simultaneously through a ML-human loop. The labeled data is incrementally added to the model, retraining it. The retrained model is used to synthetically label the unlabeled data set. The labeler is then able to pick the most useful unlabeled data to label next (Correcting mistakes). Since not all datapoints are equally valuable, Active Learning can lower the amount of labels needed to produce the best results so it is especially suited for videos.
Therefore, when you are labeling in JABS, employ an iterative process of labeling a couple videos, training+predicting, and then correcting some more labels, then training and predicting again. This will cut down on the total amount of labels needed to train a strong classifier by allowing you to only label frames which are most useful to the classifier.
Finding new videos
If you have labelled most of the videos in your project and are not satisfied with the amount of examples of that behavior in the project, you can use a weaker classifier trained on that project to find new videos to add to your project. Use your current classifier to infer on a larger available dataset. The videos which have the most predictions for your behavior can be added to your folder for more behavior examples and more examples of mistakes to correct.
Ground Truth Validation
Once you have a classifier you want to validate, it may be helpful to densely label a set of ground truth videos to test your classifier on. The simplest way to validate is a frame-based approach of counting the amount of true positives, false positives, true negatives, and false negatives for your classifier. You can use these to calculate Precision, Recall, Accuracy, and F1 beta.
However, it is important to note that while machine learning techniques are often evaluated using frame accuracies, behaviorists may find detecting the same bouts of behavior more important than the exact starting and ending frame of these bouts. Even between two humans labeling the same behavior, there are unavoidable discrepancies in the exact frames of the behavior. Consider the folling example where 4 annotators labeled grooming bouts:
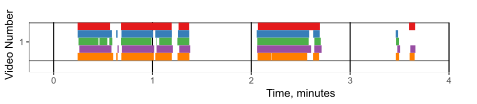
Though many of the same bouts are found by all annotators, taking a frame-based approach may cause the agreement between annotators to seem deceptively low. Therefore, you may wish to pursue a bout-based agreement for validation.